How predictable... Diving into OKCupid data
Dating Data: Who are you?
Dating sites are now ubiquitous. Whether you think that’s a good thing or a bad thing is up to you. The fact of the matter is, online dating has seen a significant increase in popularity over the last decade, and resulted in an industry worth over $2 Billion. One thing that’s difficult to refute is dating apps create a whole lot of interesting data. Which is why when faced with the challenge of building out a project using classification algorithms, what better place to peek under the hood of the human condition than a bunch of people looking for love… or something like that.
Back in May of 2016 Reddit, and the internet at large had one of it’s usual freak-outs about a recently released Dataset. At issue was data taken from 70,000 users which included more than 2500 questions which power OkCupid’s matching algorithm. I’m not here to have a discussion on the ethics of releasing this data to the public, I believe both sides have valid arguments, you are invited to make that decision on your own. Suffice it to say, for my exploration, I used the anonymized version which was released after the two danish PhD candidates responsible- Emil Kirkegaard, and Julius Daugbjerg Bjerrekær, weathered the ensuing shit-storm that came from the original release which included usernames and the city the user was located in.
The Question:
Can we accurately predict certain qualities of a person based solely on their answers to at most 20 of the OkCupid questions?
Fortunately, the answer turned out to be a relatively simple one:
Yes, yes I can.
The Method: The data is in pretty good shape. The goal of the release was to make a strong research dataset available to the public, as that can be a rare thing to find. In that I believe they succeeded. The steps taken prior to modeling are as follows:
-
Identify the top 300 most responded to questions
As I mentioned earlier, there were 2500+ questions included in the dataset. While most of the questions are interesting in their own right, many are so sparsely responded to that their inclusion will do more harm than good. I’m interested in dense data as I won’t be inferring any NaN values. Thus the set will be filtered down to the top 200 most answered questions.
-
Separate into binary categories
In order to get the best performance from the classification algo’s each possible response to a question will need to be it’s own column. Questions have between two and four response options. Responses can be ordinal or nominal depending upon the question. The get_dummies() function within pandas does a great job of splitting the questions up into the correct format.
-
Pick a question
First I identified a question that I wanted to predict. Once that was known, I ran a logistic regression model on that question against the entire dataset, and looked at the resulting coefficients. The strongest coefficients were recorded, and the model was re-run, not only did this generally improve performance, it gave me a pool of questions that I could use for future predictions.
-
Repeat
I went through this process for 15 questions that seemed like interesting categories to predict. I selected 8 that ultimately performed the best with the 20 questions that I wanted to use as input variables. Further testing may well prove that there are other categories that are effectively predicted by these 20 questions.
-
Combine
In the end the application uses a unique logistic regression model for each prediction. These models are combined to run seamlessly together in a flask app that allows the user to play around with the questions to see how the input changes the predictions.
The prediction categories
The probability that the particular category applies to you is returned upon filling out the questionnaire.
- Are you male or female?
- Is art important to you?
- Have you tried drugs harder than pot?
- Do you google someone before the first date?
- Are you open to the idea of an open relationship?
- Do you spend more money on clothes or food?
- Will you date someone that keeps a gun in the house?
- Were you picked on a lot in school?
Additionally the app provides some interesting interactive visualizations here are a few static examples:
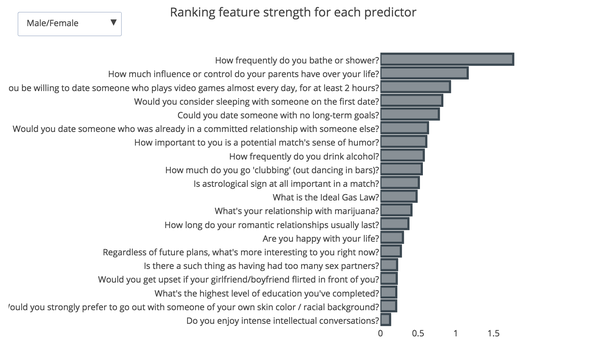
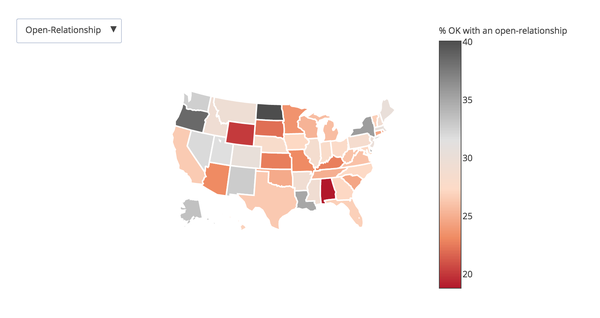
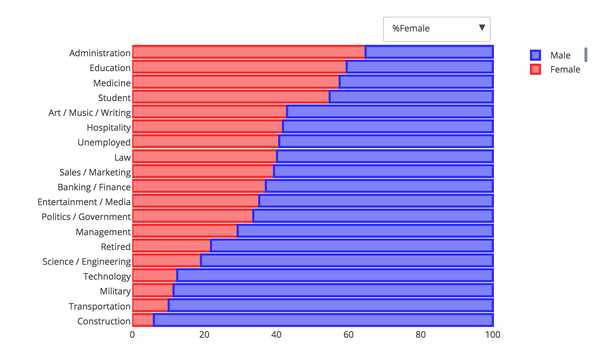
Conclusions
Ultimately I’d say this was a success. One of the main arguments for releasing this dataset was that high quality data for social science research is especially difficult to come by, and that releasing the data allows for future research on questions that may be inconceivable when the data was collected. With this I agree. Social science is an incredibly interesting field. Human beings are complex creatures, and the advent of new tools and methods has made studying the decision making process more accessible than ever, which I believe this exercise has shown. Classification in this context is an interesting path of study, and having only scratched the surface of what’s possible It’s very exciting to think about alternate exploration vectors.
Further areas of research
Seeing as my background is in fraud prevention, Something I thought about almost immediately is lies. as sad as that may sound, think of it like this: When someone is composing a profile for a dataset, they have an incentive to make themselves appear as attractive as possible. Now I’m not saying everybody lies. Most people are honest most of the time. But I would hypothesize existence of evidence hidden within the data that would suggest a “when in doubt, what answer makes me look better” approach. The challenge with this is the lack of ground truth. Given more data, say user logs relating to browsing history, profile edits, messaging history etc. I believe this could be more accurately separated out, and an “honesty index” of sorts could be calculated. I’d speculate this would make for stronger matches if incorporated into the matching algorithm…
Dear dating apps the world over, as of publication, I’m eminently employable!