Password strength with NLP
Latent Semantic Analysis re-imagined
Account takeover attacks are incredibly lucrative for criminals. The average stolen credit card can be bought and sold on the dark web for pennies, while compromised accounts fetch $3-$20 each depending upon what is accessible through them. Additionally the extent of possible damage to the victim is far greater; accounts can be drained, identities stolen personal data scrapped, the list goes on. Firms have conflicting incentives when it comes to pushing strength. Any friction in the customer acquisition pipeline is universally abhorred, and as is the case, there is a real resistance to implementing strong measures. At the same time, High profile account takeovers, are incredibly damaging to a firms reputation, not to mention bottom line, as fraudulent attacks from a previously trusted source are next to impossible to prevent. The fine line balancing act present in everything related to security and fraud prevention is certainly in full force here.
Going further: Another thing that can be harmful to websites or companies is “throwawawy accounts”. Depending upon the industry these accounts can be high risk for fraudulent, or otherwise undesirable activity. Passwords can provide a unique and candid view of a user that may differ from what is provided in the visible fields. Being able to capture this signal without compromising on security is valuable for detecting anomalies in your order stream or accounts that you may want to be wary of. Some of these techniques are already commonly employed on username and email as discussed here.
Problem: Password strength is pretty universally bad. Passwords that are difficult to crack are difficult to remember, just as passwords that are easy to remember are easy to crack. I’m setting out to build a novel method for quantifying strength in a password utilizing an approach rooted in Natural language processing.
Data: I am utilizing a dataset which includes 10 million username password combinations which were scrapped from various high profile data leaks shared on various paste sites. For now I am focusing on just passwords, however future iterations can apply these same techniques to a username password pair, in an effort to strengthen the combination.
Process:
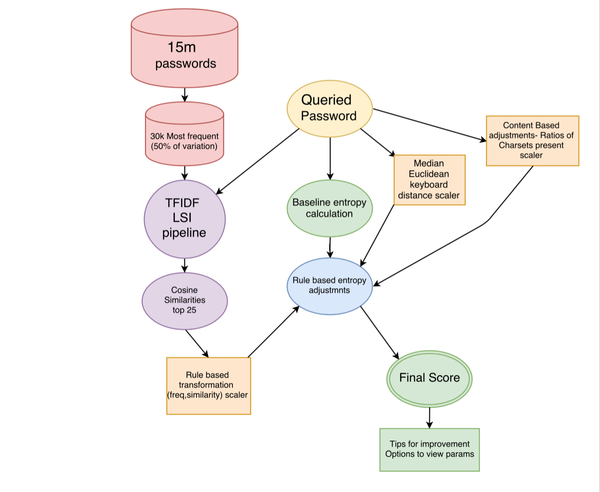
Data cleaning: Passwords are ranked by the frequency at which they occur within the dataset. Which is assumed to be representative of what will be encountered in a live use case. The passwords which represent 50% of the accounts within the set are selected as our ‘common passwords’. This leaves us with 30,000 passwords, with 10 million initial observations, the fact that 50% of the unique passwords is a 99.7% decrease in the size of the dataset highlights just how bad passwords are, and why it is that cracking tools are effective.
NLP Processing: Our passwords are then transformed into a vector space utilizing TFIDF to split them up into their 15,000 most common 1,2,3,and 4 grams. We then perform dimensionality reduction with LSI so as to create a 500 dimension common password vector space. This space is saved as a model, and a querying pipeline is put into place for future testing. When a potential password is queried, It goes through the same steps as the original password sets, It is processed through TFIDF, we convert it into the same vector space using an LSI transform, and the cosine distance is calculated for the resulting 1x500 vector. The results are sorted in descending order and the top 25 are selected. For each selected similar password, it’s degree of similarity, and it’s frequency in the original dataset is used to scale the entropy score of the password.
Content based metrics: I didn’t stop at similarity. One thing that I have noticed in going through these sets is that people like to use rows of keys as they appear on the keyboard. Many of the top most common passwords in the dataset contain this type of pattern. Now the LSI model will do a pretty good job of decrementing the score when this is present, I wanted to further boost this effect for a couple of reasons.
-
It’s a lazy way of creating a “strong” password (in the eyes of most available plug-ins)
-
It’s indicative of throwaway accounts.
As I mentioned above, passwords can be used as signal when it comes to identifying fraudulent or otherwise less than ideal activity, the obvious risk to this is that you don’t want to reveal the plain text passwords to anyone, including your fraud analyst. Capturing aggregate metrics like keyboard distance allows you to save the signal in a way that’s not susceptible to reverse engineering. In order to do this I built arrays representing the location of each key on a standard qwerty keyboard, and created a Euclidean distance function to return how far each character is from it’s neighbors. A median score is then generated for the password as a whole. With relatively few exceptions, this works well in distinguishing content rich passwords from those trying to hack the password policy requirements. Again this is used to scale the baseline entropy score.
Here is a diagram for how data flows through my system:
Testing:
- A user inputs a password to test.
- That password has it’s baseline entropy calculated.
- The password is converted into the LSI test space and has it’s similarity entropy scaler returned.
- The password has it’s euclidean keyboard distance processed, and an entropy scaler is returned.
- The password has some content and character ratios checked which return their own entropy scalers.
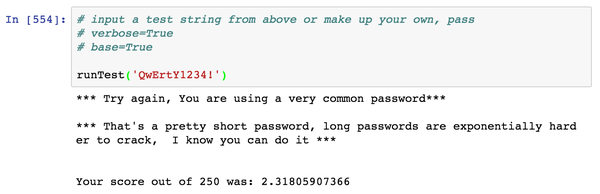
- All entropy scalers are applied to the original baseline entropy, and from that a relative score out of 250 is returned.
- Any weak points within the password are reported back to the user to guide them in creating more secure passwords.
Future steps:
- Benchmarking against the existing plug-ins, such as:
- Benchmarking against existing password Cracking software
- This will hopefully identify weaknesses to my approach
- Expand upon the existing password database to build a more complete ‘common’ list.
- There are many existing word lists available such as this which power many of the password cracking tools out there. Adding those within our LSI space should increase accuracy.
- Build in similarity metrics for username as well. It’s yet unclear if username can be used to predict password, although I would hypothesize it can. With a little testing this could be determined, and if we reject the Null, this kind of functionality could be added, as username is something that would likely be known in an attack scenario.
- Work towards making it more performant.
- Once the ground truth that we’ll get out of the benchmarking is known, we can begin making adjustments to the size and scope of the vector space we’re using, this should go a long way in making the tool lighter weight.
- Code cleanup and packaging for easy implementation and added flexibility and tuning.
Conclusions:
I’m quite pleased with the results I’m able to achieve with this tool. I’ve never seen an NLP approach to building stronger passwords, and for a week and a half’s worth of work, the product I made shows good viability. I’m fascinated by this space, and the challenges surrounding nailing good balance on that thin line between security and ease of use. Password related metrics are underutilized in the fraud detection space in my opinion, and I believe this goes a long way in building a good solution to maintain both security and signal. There’s still work to be done, but I’m very pleased with the results.
Update 03.28.17: I’ve added to and refactored this project, most important addition is a method for extracting secure features from a password prior to encryption for fraud analysis. Take a look at the project repository for more.